At Just Eat, we’re constantly asking more of our data platform. Frequent requests for information mean new data has to be added to our Data Lake on Google Cloud Platform (GCP). In this post we’ll discuss the various processes that we carry out to ingest data into our data lake. We’ll move on to document a high level view of our architecture and wrap up by looking at the tenets that are carried through into the implementation.
Much of the ingestion process is repetitive; the same high-level steps are generally carried out for each ingestion job regardless of source system nuances. These steps are:
- Data Retrieval: Typically, the first step in any ingestion process is to extract the data from the source system. We ingest data from over 100 heterogeneous systems, these systems may be internal or external to Just Eat. Data is transferred using a variety of mechanisms (S3, GCS, database extract, HTTP, FTP, etc.), or streamed into our real time ingestion API.
- Schema Inference & Evolution: Due to the development cycle of any product or data feed, changes are inevitable. To be able to handle additional data points and removal or change of existing ones, we need to have a way to track and handle schema changes.
- PII Identification & Obfuscation: We take data privacy seriously here at Just Eat, ensuring we handle all of the data that we consume with care. As part of our ingestion, we need to identify any potential PII data, anonymise it and store it correctly. This also ties in with our Subject Access Request and Right To Be Forgotten processing, enabling us to comply with GDPR.
- Data Loading: After retrieving the data, inferring its schema and ensuring it’s been through the relevant anonymisation process, it must finally be loaded into our Data Lake.
Introducing Airflow Ingest
The data engineering community has helped curate a number of tools to orchestrate the above processes. There are a various different platforms that support such orchestration. We’re big fans of Apache Airflow. It scales extremely well and offers us the ability to enhance and extend it. In addition to this, Airflow has great community, helped by the fact that its been taken into the Apache Software Foundation. We’ve been running Airflow since 2016.
After some experimentation, we eventually settled on a CQRS architecture (separated ingestion from consumption). This paradigm saw the formation of three new tools, each with a razor-sharp, focused purpose.
Airflow Ingests (as it’s aptly named), raison d’etre is to provide a highly flexible and configurable environment for extracting data from an arbitrary source and landing it in its raw form in GCS. No transformation or outbound data feeds, just ingestion.
The five pillars of our data engineering toolkit, Ingest, Optimus, CAS, Egress and Orchestrator.
Laying The Foundations
Before we dive into building a DAG (Directed Acyclic Graph to the uninitiated) on our new ingestion platform, let’s lay some ground rules which prevent us from writing lots of repetitive code that’s difficult to maintain, reuse or extend:
System Agnostic: An ingestion DAG’s sole purpose is to move data from source to target (our data lake). We tend to create an abstraction around source file systems (Google Cloud Storage, S3, SFTP or else) rather than the business logic.
This allows us to code a limited number of generic, configurable ingestions that implement the processing steps mentioned in the introduction (extract, schema inference, PII handling and loading). The process of adding a new ingestion is as simple as adding a few lines of config as we don’t need to treat a particular source system differently.
Organisation Is Key: Data Lakes aren’t highly curated, standardised stores of data. They store data in varying formats, with schemas inferred at read-time. This doesn’t mean they need be to organised like a teenager’s bedroom.
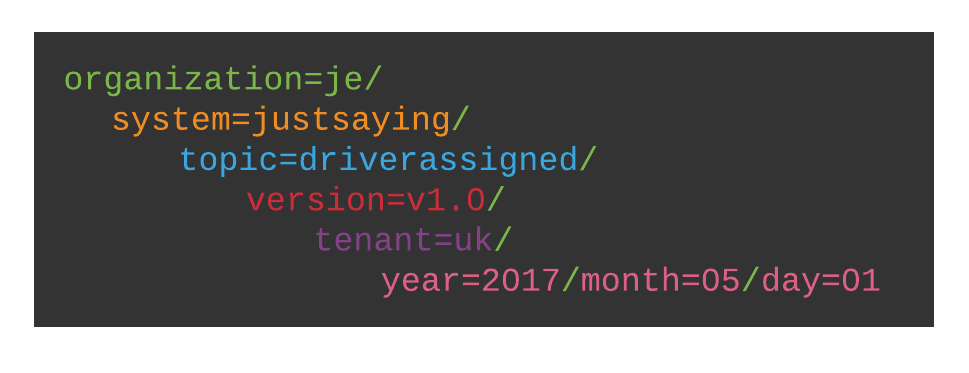
We ingest over 100gb of data per day; to keep this data manageable we’ve chosen to enforce a naming convention throughout our ingestion processes. Data is organised using a number of sub divisions; data on both GCS and BigQuery is logically structured by organisation, system and topic. Further separation is created by versioning data and introducing date partitioning. Some conformity of the data into a standard file format (in our case Gzipped JSONL files) also eased processing downstream.
Don’t Reinvent the Wheel: Airflow provides some great inbuilt features (sensors, hooks and operators etc.) to encapsulate common operations. We made use of these features throughout our jobs but soon realised most of our DAGs looked similar. Actions like moving data from GCS to our Data Lake (BigQuery), would appear in most of our ingestions. We were instantiating the same operators with the same parameters in a lot of our DAGs.
We rapidly came to the conclusion that a Factory Method would allow us to facilitate reuse, extension and testing. As a side effect, this also made our DAGs much more readable and compact.
In a similar vein, Airflow’s architecture allowed us to encapsulate common operations into our own Hooks and Operators (extending BaseHook and BaseOperator). We earlier spoke of metadata management being one of our key tasks within ingestion – Schema Inference & Evolution. Calling out to our Schema Registry service became a matter of adding a new custom Operator to your DAG, naturally this too fell into our Task Factory.
Think Big: We’re hungry for data – data powers all of our decisions at Just Eat – the data lake even contains output from JIRA to help us analyse our workflow. Our ingestion process has to be able to cope with future demands without being rebuilt from the ground up.
Airflow isn’t built to do the heavy lifting, but rather orchestrate all the work. With that being said, when you’re running 10,000+ tasks per day, distributing your workload makes life easier. Resilience and scalability can be delivered by scaling worker deployments using Kubernetes, having a number of pods available to execute Airflow tasks.
This also allows us to cope with varying requirements and resources, dependent applications can also be varied per worker class. For example, we have some tasks that are memory intensive, to handle this we have a high-memory-worker that work can be distributed to.
Summary
In this post we’ve introduced Data Engineering at Just Eat, focusing on one of the key functions of a data team — Ingestion. We talked about the main sub-tasks executed during ingestion, touching on how they actually operate.
This paved the way to discuss our Airflow-centric tooling, introducing our ingestion platform and the surrounding tools that facilitate transformation and egress. We finished up by drilling down into the key paradigms that are followed within implementation.
In subsequent posts, we’ll delve into some implementation specifics and get our hands dirty with some code samples.
Nice post!
I wish I could see the author’s name, though… 😉
Would like to know more about incorporating schema changes in the workflow due to the development cycle.
Comments are closed.