JUST EAT’s UK restaurant search was based on postcode districts, but this was a very rigid approach, not very accurate for large districts and was only updated periodically. What we wanted was a way to customise the delivery areas, per restaurant, at a greater level of accuracy with near real time updates. With the power of Elasticsearch and some very clever maths we were able to create and search restaurant delivery areas using polygons.
NoSQL implementation
We ran a ‘Search Lifecycle’ scheduled job (multiple times per day) that collated all of our restaurants and the districts they delivered to, creating an inverted index with the district as the key and a collection of the restaurant IDs as the value.
When a consumer searched for SE1 1AA we searched only on the district, so stripping 1AA and searching for restaurants that deliver to SE1, which mapped to a key in our inverted index. This allowed fast retrieval of search results by postcode.
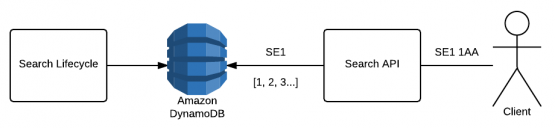
search lifecycle indexing workflow
NoSQL limitations
One of the main drawbacks of the NoSQL implementation was that delivering to whole districts is not the same as how the restaurants work day-to-day – in reality a restaurant is willing to travel a certain distance, internally we mapped this to districts. Districts can be very large, a restaurant that delivers up to, say, two miles from its premise may cover a certain section of a district, but they may not necessarily want to deliver to all of it.
There were two ways to fix this…
- Change to use more accurate postcodes ie. sectors like SE1 1xx (where the xx part is ignored).
- Use polygons to map out exact areas where a restaurant will deliver.
We decided on option two, polygons. The second option allows us to have any custom shape that can be drawn on a map which is more accurate than districts and easier to manage than sectors, the main disadvantage is that it requires a wider change to both our indexing process and our Search API.
Polygon all the things
When looking at different implementations of polygon search we looked at Postgres and Elasticsearch, we decided on Elasticsearch because of the added features that it provides on top of polygon mapping.
There were a number of factors we needed to work out before we could implement full postcode searching…
- How do we transform our current districts into polygons?
- How do we search an Elasticsearch index for restaurants based on a full postcode?
Transforming districts into polygons
We purchased polygons for all districts in the UK and saved this to a DynamoDB table, with the district as the key and the collection of points as the value, creating an operation in an existing API to return the polygon based on the district.
We already had an API operation for saving delivery areas (districts) for a restaurant, and didn’t want to have to change how this behaved so we published an SNS message using the JustSaying message bus, the message contains the restaurant ID and list of districts. We have an existing worker service which listens to restaurant messages and performs long running tasks, we added a new handler to listen to listen to this message and publish an enriched message to be consumed by a different worker service. This service is used for transforming the message into a GeoShape to be saved into the Elasticsearch index.
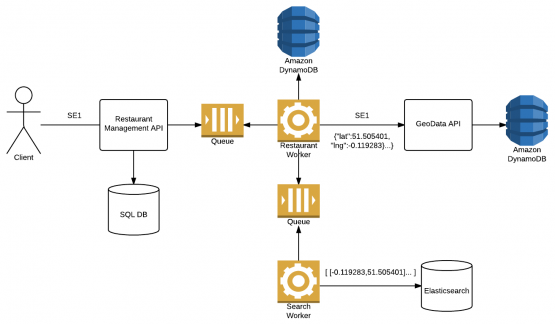
elasticsearch document indexing workflow
Searching full postcodes using Elasticsearch
First we had to design the mapping for our index.
We decided on using the nested type to store the delivery areas because it allows us to add additional metadata to each area for future features.
{
"properties" : {
"deliveryAreas" : {
"properties" : {
"area" : {
"type" : "geo_shape"
}
},
"type" : "nested"
},
"restaurantId" : {
"type" : "integer"
}
}
}
Searching for a full postcode requires us to turn the postcode into a set of latitude and longitude coordinates, so SE11AA becomes latitude 51.501961 and longitude -0.091652.
We use the GeoShape Filter to search the nested child documents.
{
"_source" : false,
"query" : {
"filtered" : {
"filter" : {
"nested" : {
"filter" : {
"geo_shape" : {
"deliveryAreas.area" : {
"relation" : "intersects",
"shape" : {
"coordinates" : [ -0.0916520, 51.501961 ],
"type" : "point"
}
}
}
},
"path" : "deliveryAreas"
}
},
"query" : {
"match_all" : {}
}
}
}
}
You may notice the _source = false part of the query. When we search for restaurants we only need to know the IDs as the consumer only wants to know which restaurants deliver to them, not which delivery area they fall into, as the restaurant ID is the ID of the document no fields are required. Setting _source to false improves performance as less data is returned for each search.
Custom polygons
Once we had all districts mapped and indexed into our Elasticsearch cluster we wanted to address the original feature that polygons were meant to address, delivery distance limiting.
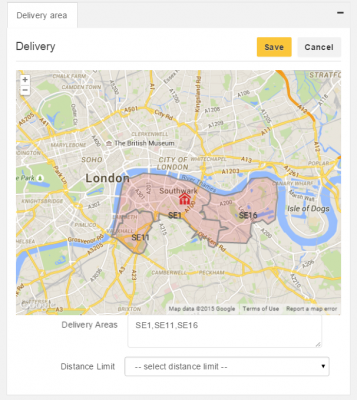
delivery areas without distance limit
Based on the location (latitude and longitude) of the restaurant and a mile limit (as the crow flies) we wanted to clip the existing districts to create new polygons, but how did we achieve this?
We used Trigonometry to create a circular polygon from the restaurant location and a mile limit and with the coordinates from the district polygon and with the help from an open source C# library Clipper we were able to create a new set of polygons based on the point intersections.
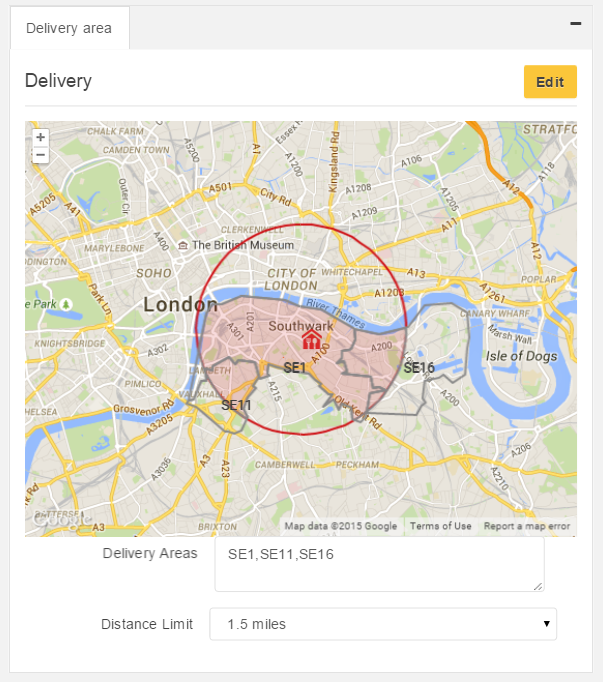
delivery areas with distance limit
GeoShape queries work based on coordinates, the coordinates for the polygon could be a district, a circle or even the shape of a penguin, as long as the consumer’s location falls into that shape it doesn’t matter what it is.
What have we learnt?
We were relative novices when implementing our first Elasticsearch index, we had lots of obstacles to overcome, here are just a few of the things that we learnt along the way…
- If you only require the ID to be returned in a query then omit the _source field, reducing the overhead of the query and improving performance.
- Create a read alias for your live index, allowing you to hot swap to a different index in case it needs to be rebuilt.
- Create a write alias, this can be made to have multiple indices so you can write to more than one index at a time. Or, with the use of the read alias you can rebuild your entire index without affecting the reads, this can be achieved by setting the write alias to a new index on a node that is not currently in the same cluster and having replication disabled.
- Setting a decent refresh interval can greatly increase how quickly you can index your documents, you can see some of the performance benefits from this blog post, we decided on 60 seconds, the gains seem to flatline much after that.
- Dynamic mapping can be a curse, especially with polygons. A polygon is an array of arrays of arrays of coordinates, if you do not explicitly set the mapping to geo_shape then it will set it as an array of numbers and your queries will not work.
We’ve only scratched the surface of what can be achieved with Elasticsearch, our indexing architecture is a foundation to easily extend and adapt new search features.
All sounds very good from a technical point of view however however recently the number of places your iOS app returned for my post code has dropped to 2 where as before there would be more than 10 and I know that all the old places still deliver. If I use a postcode close to my favourite takeaway then it comes up but it no longer appears in the list for my postcode and they still deliver here so the new method doesn’t work for me and I can’t use the app any more. No matter how good your method sounds in theory if in practice it doesn’t return the correct takeaways then it is useless.
Hi Richard, I’m Dave one of the Tech Managers at JUST EAT (my guys, including Matt, were responsible for the above feature).
My apologies your options for food have been reduced! To give the best possible service to their customers our restaurant partners have the ability to adjust their distance limit so that they cover the customers they can give the best delivery experience to (warmth of food, distance, busy traffic areas etc). If you have a particular restaurant you miss I’d recommend asking the restaurant if they want to change their limit, or visit http://www.just-eat.co.uk/help and chat to one of our agents. They’ll be able to take your postcode and have a closer look at your particular case, forwarding onto the right team any potential improvements/adjustments.
Thanks for your feedback, we really appreciate it!
Hi Dave,
Thanks for the update. I could understand that if it was just one or two takeaways, but just about all of them have dropped of the list. Out favourite one still deliver to us but I now just ring them direct so it’s not a real problem to us as it’s also cheaper this way even if slightly less convenient. It’s just you guys that are missing out on the business re-directs now.
Thanks for the reply though.
Richard
Thank you for this. It is a great share. One question. You have a section titled “NoSQL Limitations”, but the section didn’t outline any limitation in NoSQL databases. What limitations of NoSQL did you encounter?
Comments are closed.