Introduction
Why ServiceStack?
“ServiceStack is a simple, fast, versatile and highly-productive full-featured Web and Web Services Framework that’s thoughtfully-architected to reduce artificial complexity and promote remote services best-practices with a message-based design that allows for maximum re-use that can leverage an integrated Service Gateway for the creation of loosely-coupled Modularized Service Architectures.”
This article is a detective story about performance issues we encountered with the free version of ServiceStack framework and how we managed to eliminate them.
Background
Since August 2013 ServiceStack has moved to a self-sustaining commercial model for commercial usage of ServiceStack from v4+ onwards. From v3.9.62 Release Notes: “v3.9.62 marks the point where v3 goes into feature-freeze to make room for the future v4 commercial version of ServiceStack.” While the vast majority of our APIs at Just Eat have been migrated to or initially spun up with other frameworks, there are still a couple of elephants in the room that keep on giving.
AppDynamics
About a year ago from the time of writing (2018) Just Eat embraced AppDynamics – a powerful microservices monitoring tool that keeps an eye on every line of code and instantly sends performance counters providing comprehensive telemetry on the health of our services.
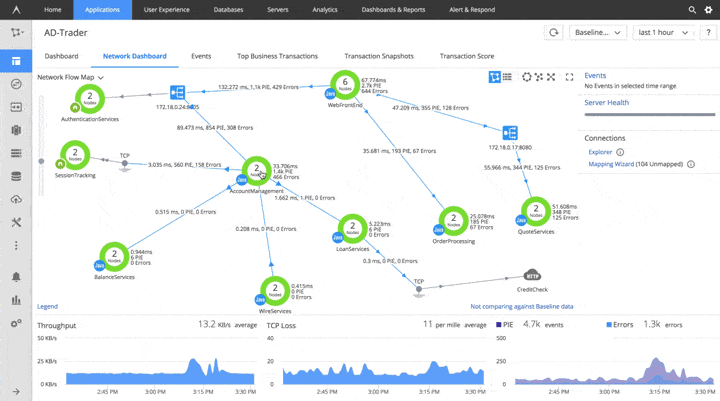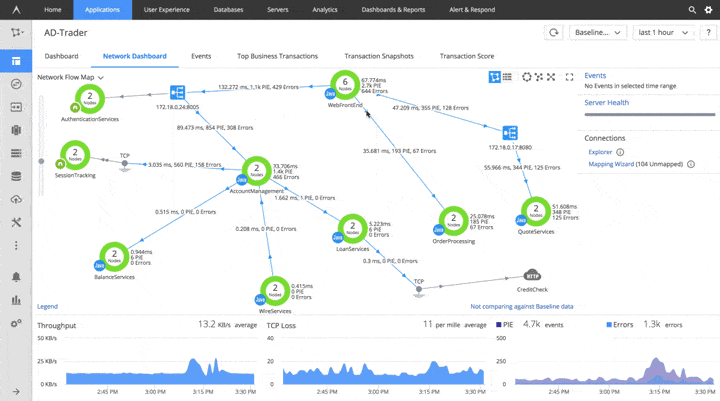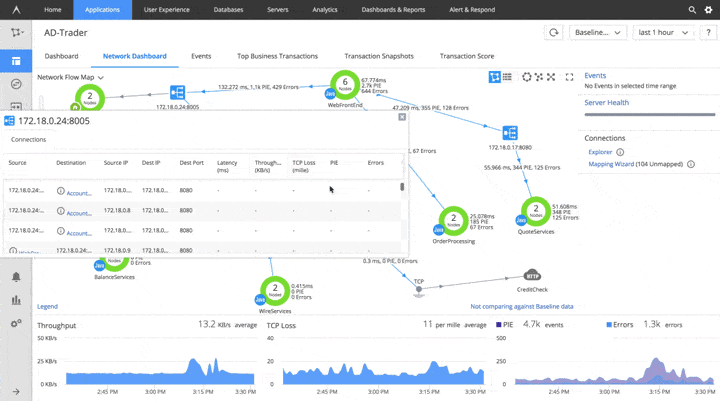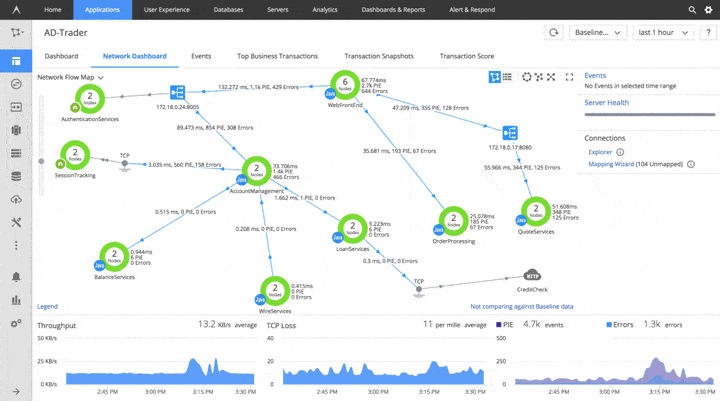
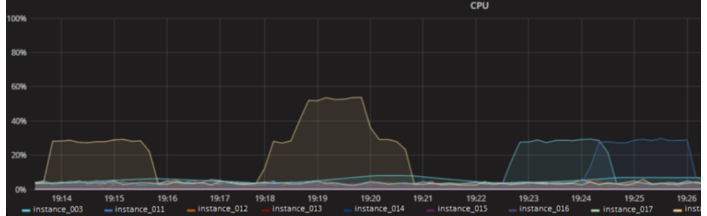
Once we baked a new Amazon machine image (AMI) with AppDynamics built-in and rolled this out to our production environments, we encountered sporadic off-peak and quite painful at-peak CPU spikes on EC2 boxes running ServiceStack services on them.
 (figure 1.1)
(figure 1.1)
In short, whenever we combined AppDynamics & ServiceStack we could see a very strong correlation between CPU spiking and said combination of ServiceStack and AppDynamics. This was escalated to AppDynamics for investigation and many iterations and attempts at uncovering the issue ensued.
Eventual AWS based deadlines forced us to upgrade our underlying AMI without making use of AppDynamics and to our surprise, the issue was again present, this time without AppDynamics.
Further extensive experimentation followed and every possible permutation of including and excluding AppDynamics, Codedeploy upgrades and Spectre meltdown patches… finally pointed towards a Windows Update that got rolled into a newly backed AWS AMI.
Sleeves rolled up!
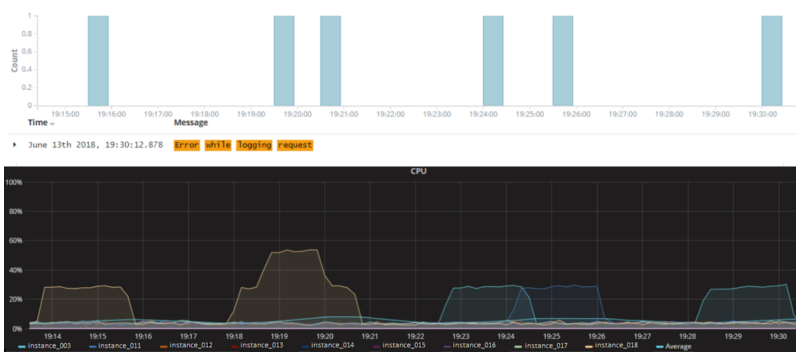
Having this finding in mind, we tried to look at things from a different angle. While trying to match CPU spike timestamps with log entries, we noticed that a specific error log message (“Error while logging request”) showed correlation with the relevant CPU spike metrics.
 (figure 2.1)
(figure 2.1)
Having proved that this error had always been present in our logs, the question became: Why did this not cause any performance issues before the specific Windows update got installed and applied to the server instances?
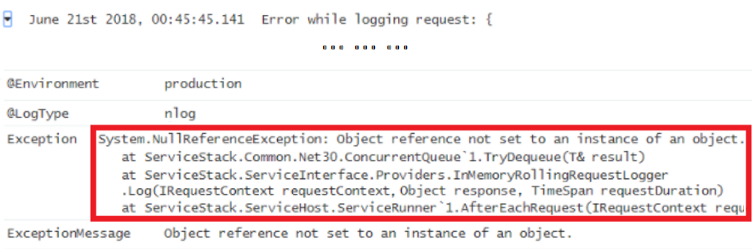
Looking closer at the error that have not caused any serious implications before, we can see that the underlying cause of the error is a NullReferenceException:
 (figure 2.2)
(figure 2.2)
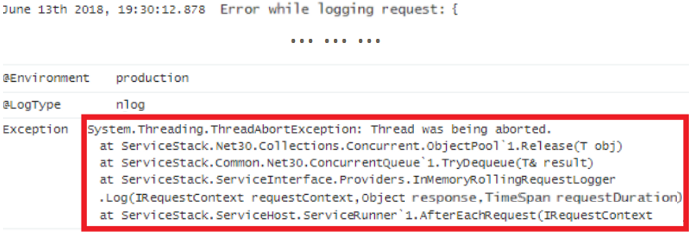
Looking at the corresponding error as produced by the “Bad” server instance – leading to high CPU spiking – we can see a less trivial issue as the underlying exception:
 (figure 2.3)
(figure 2.3)
One of the key parts of the puzzle was the discovery that the ThreadAbortException was being thrown exactly 120 seconds after the request came into the service. In turn, the CPU spikes also lasted for exactly the same amount of time.
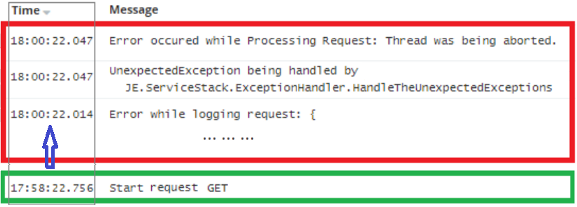 (figure 2.4)
(figure 2.4)
This implied that the request was being processed way too long and eventually got terminated by IIS after the configured timeout had expired (by default, the connection timeout for IIS is 120 seconds).
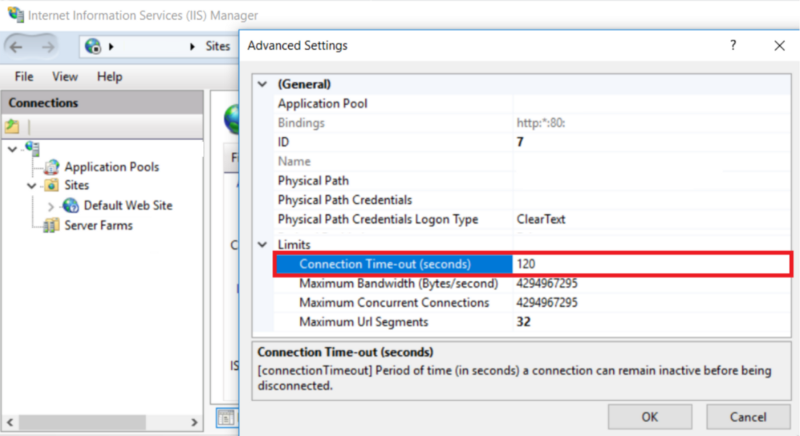 (figure 2.5)
(figure 2.5)
The latter got us thinking that it could be a deadlock or more likely a spin-wait lock – which is a while-loop causing CPU heat up when a lock does not release for a relatively long time – since the spikes lasted for exactly 2 minutes long then cooling down immediately after thread termination.
Surgery
Finding deadlock causing code by sifting through source code is not a trivial task. However, we did have the stack trace of exceptions thrown from ServiceStack’s ObjectPool.Release() method (shown in figure 2.3), which was called from the ConcurrentQueue.TryDequeue() method.
If you look at the ObjectPool.Release() method, you find a home-made spin-wait lock implementation – which is in fact not fully thread-safe – that used to cause the lesser impactful NullReferenceException (shown in figure 2.2).

The fact that this method threw different exceptions whilst running on machines with different Windows updates gave us reason to suspect that the produced MSIL was being JIT-compiled differently.
To try and prove that this is the case, with the help of BenchmarkDotNet, we implemented and ran a small tool. The tool takes the mentioned ServiceStack “spin-wait” code, and produces some corresponding assembler code against the differing Windows updated machines.
Here are the results:
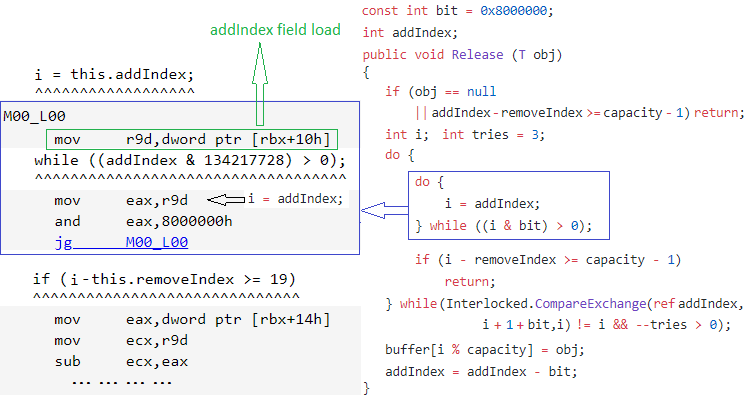
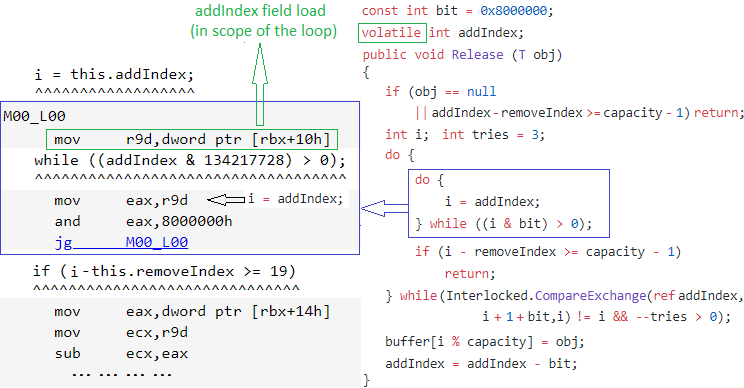
When running on the machine with the suspicious Windows updates, we see that the addIndex field load is hoisted out of the loop. This effectively made the loop infinite when the condition in the while statement is met at least once and usually happens when two concurrent threads are trying to acquire the lock simultaneously:
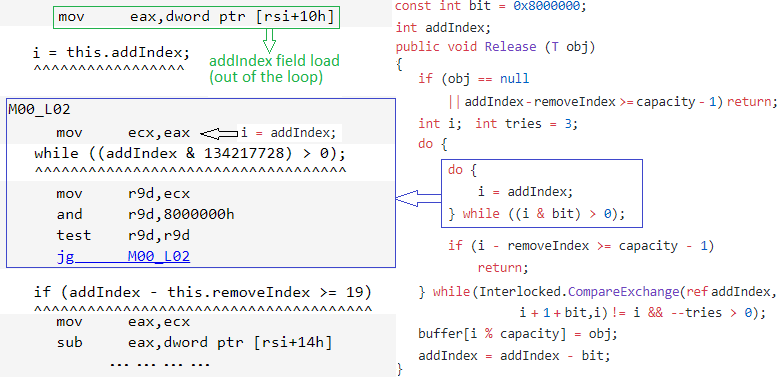
As long as the addIndex field is not marked as volatile, this JIT optimization behaviour is completely legitimate.
The BenchmarkDotNet utility also helped to identify what changed in the environment after the suspected Windows update installation. In spite of the target runtime framework being kept at version 4.6, the next-generation RyuJIT normally shipped along with .NET Framework version 4.7 was used regardless, and some new runtime optimizations kicked in.
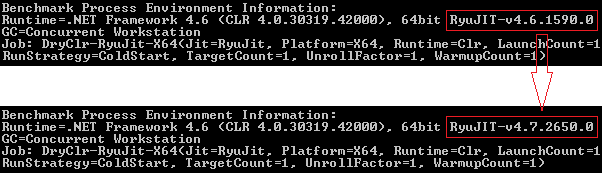
Another BenchmarkDotNet test helped to prove that marking the field as volatile suppresses the mentioned optimization causing this side effect:
Solution!
By the time this article was published an appropriate pull-request had been raised and merged into the ServiceStack v3 branch and we are waiting for the NuGet package to appear with the fix. But for the sake of a dramatic ending, this article will tell you what we did to eliminate the problem while the fix was on the way to the ServiceStack Github repo.
As Microsoft has been receiving loads of reports about application behaviour affected by the RyuJIT compiler, they provided a list of recommendations to mitigate such problems. One of the options was to disable RyuJIT and fallback to the legacy JIT64 compiler. None of the disabling mechanisms were suitable for us – the per-application config does not apply to ASP.NET applications and the other two options seemed risky and tricky in terms of deployment. The rest of the recommended work basically revolves around suppression of various optimizations and would be considered only as a last resort.
So instead of mitigating performance issues by general degradation of service performance, we injected an alternative implementation of ServiceStack’s RequestLogger. The safest way was to replicate this implementation with the one-line change replacing ServiceStack’s ConcurrentQueue (which depends on the dodgy ObjectPool) with a reliable “native” .NET ConcurrentQueue implementation:

One has to be aware that to inject a custom implementation of an interface to substitute ServiceStack’s own stuff, you have to tell its IoC container to give preference to your registrations:
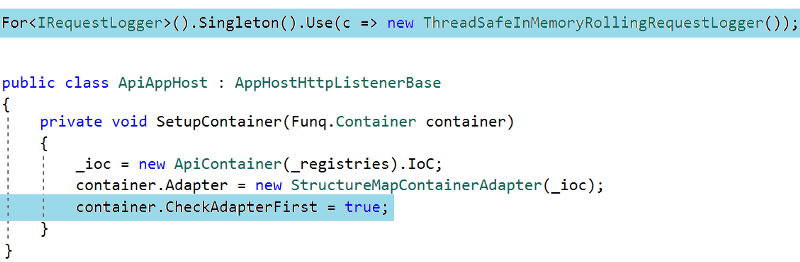
In the end, we pushed this out to Production on the newest AMI with AppDynamics monitoring the performance of our services with the issue finally resolved.
Conclusion
- In a multithreading environment, you should be extra careful with fields accessed concurrently. E.g., as demonstrated above, while a thread is expecting (by design) another thread to change the state – runtime optimizations may play tricks on you. Protect yourself with thread-safe constructions provided by the chosen language.
- The .NET Framework is not perfect, and everything has its own pitfalls. No matter how experienced you are, you have to find a very sound justification to implement something that has already been done and well tested (ConcurrentQueue and SpinWait being a good example here – assuming I’m not missing anything obviously bad about them). Otherwise, chances are that your homemade handcraft will turn out as another weakness in your software application.
- Microsoft has been doing a great job with performance improvements in their software environment, and it’s rare, but it does happen that these improvements may lead to a stable implementation behaving differently within the context of a newer environment (causing race conditions, etc).
- When choosing an off-the-shelf solution, you have to embrace the fact that this in itself is no silver bullet. An example here would be .NET Core, which is a good stuff, but still is being continually enhanced with bugs fixes and so on. Just Eat engineers also contribute to this by raising issues and making feature requests.
About the Author
This blog post was written by Dmytro Liubarskyi, an Engineering Lead and Acting Technology Manager of the Payments team at Just Eat.