The JUST EAT platform
JUST EAT is the world’s leading online takeaway ordering service; we operate a web portal that allows people to order takeaway from their local restaurants. That portal is hosted on our platform and that’s what we build here in the Technology team – the JUST EAT platform. We run on Amazon Web Services and make use of many of the AWS services, such as EC2, CloudFormation, S3, etc. What we’re building is a highly available, resilient system. We have lots of traffic from lots of hungry customers (particularly on weekends) and, sometimes, things break. Network connections fail, databases die, queries time out, APIs throw exceptions. Failures happen in all software systems, but the greater scale of cloud systems forces us to consider these issues in our designs early.
Availability
So, we’re building a highly available system and that means that we need to make sure that our building blocks, i.e. the AWS services that we use, are highly available. It’s useful to consider that there are two types of services in regions.
- Those where you are expected to do some work to make the service highly available. With EC2, for example, you can choose to run instances in Auto Scaling Groups spanning multiple Availability Zones.
- Those where AWS have built greater availability into the service itself, but where you may be expected to do some extra work to be resilient to the failure of that service within a region. Some examples of these services are SNS, SQS or SES.
At JUST EAT, for the services that we use, we’ve already worked to increase the resiliency of that first type of service and now we’re working through the latter types of services. We use SES: we can now cope with temporary outages there. With our platform becoming increasingly dependent on messaging, via SQS and SNS, it’s important for us that we look to increase the availability of those services next. Being fans and users of much open-source software, we decided that we’d document our development of this strategy in the open, here on our blog.
Region failure (a.k.a. what happened to eu-west-1?)
Amazon services exist inside geographical regions. You can see a matrix of where each service is offered from on this Amazon web page. When I, for example, create a queue with SQS, I choose to create that queue in a particular region. Now, as mentioned above, things break sometimes. Outages occur. It’s very rare for an AWS service to become unavailable for an entire region, but it can and does happen. Netflix, for one, have blogged about some of their experiences with cloud outages. For a system like the JUST EAT platform, which has become heavily reliant on messaging via SQS and SNS such an outage could have a significant impact on our business. Broadly, if we had the ability to switch from using SQS/Ireland to SQS/Frankfurt, then we could minimize that impact. But how?
Decisions, decisions…
Our open source messaging component JustSaying is built on top of SQS and SNS and is how our teams do AWS messaging at JUST EAT. Teams are pretty independent internally, free to choose the best tools and solutions for their domain, but we do recommend using JustSaying if you’re doing messaging on AWS. Building region failover support into that component seems like the best way to build it into the platform. So, what’s the solution? What are our options? We spent some time researching and thinking about how we could build an AWS system resilient to these failures and came up with three possible architectures.
Option 1: Active-Active
‘Publish messages to all regions and subscribe to messages from all regions.’ 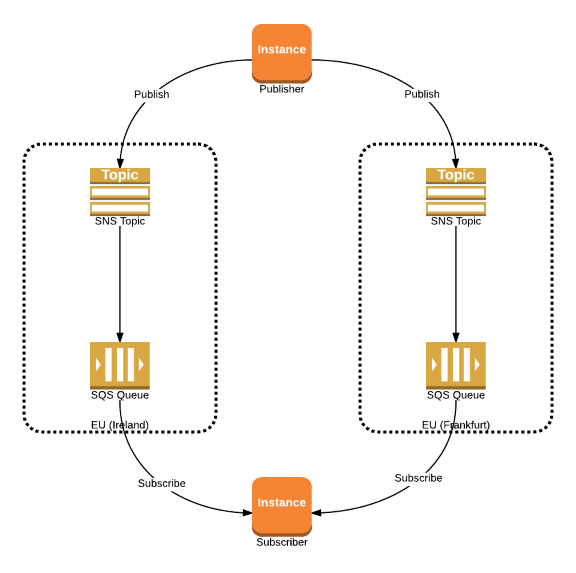 In the case of two regions, this solution results in subscribers receiving two copies of each message and therefore needing logic to ensure each message is only processed once. On the other hand, we wouldn’t need logic to detect a failure or switch the ‘current’ region.
In the case of two regions, this solution results in subscribers receiving two copies of each message and therefore needing logic to ensure each message is only processed once. On the other hand, we wouldn’t need logic to detect a failure or switch the ‘current’ region.
Option 2: Active-Passive Subscriber
‘Publish messages to all regions. Subscribe to messages from the primary region, switching to the secondary region when an outage is detected.’ 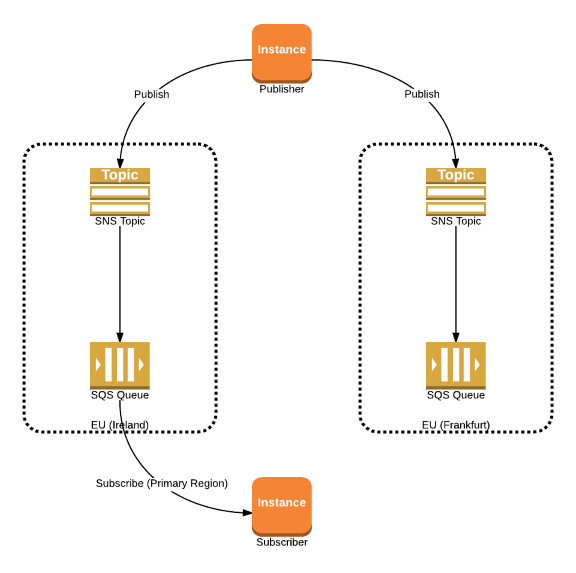 Unlike the Active-Active option, this solution requires that we can detect the outage and to to respond by changing the subscriber to listen to messages from the secondary region. Also, during the failover, it’s possible that the subscriber could receive a particular message once from each region, necessitating the same deduplication logic as the previous solution.
Unlike the Active-Active option, this solution requires that we can detect the outage and to to respond by changing the subscriber to listen to messages from the secondary region. Also, during the failover, it’s possible that the subscriber could receive a particular message once from each region, necessitating the same deduplication logic as the previous solution.
Option 3: Active-Passive Publisher
‘Subscribe to messages from all regions. Publish to the primary region, switching to the secondary region when an outage is detected.’ 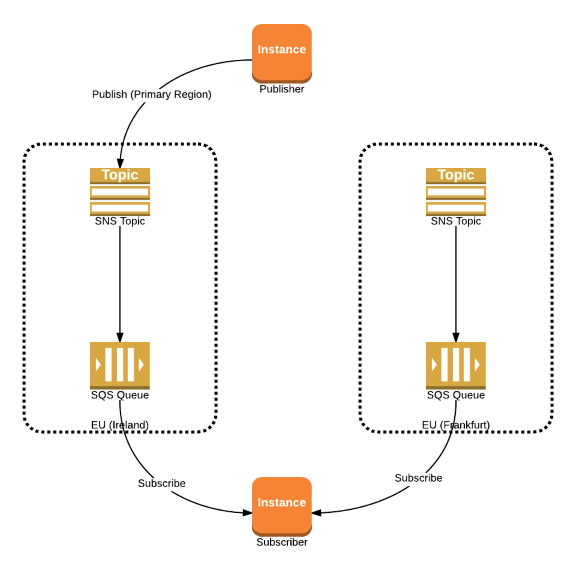 Again, this option requires us to be able to detect the outage. Unlike this previous option, however, when we detect a problem we would switch the publisher to direct messages to the secondary region. For our needs, we decided that option 3 above works best. Active-Active would require us to ‘de-dupe’ messages and Active-Passive Subscriber needs us to tell every subscriber to update and listen to the new region. Since we have more subscribers than publishers, that makes Active-Passive Publisher a better solution for us.
Again, this option requires us to be able to detect the outage. Unlike this previous option, however, when we detect a problem we would switch the publisher to direct messages to the secondary region. For our needs, we decided that option 3 above works best. Active-Active would require us to ‘de-dupe’ messages and Active-Passive Subscriber needs us to tell every subscriber to update and listen to the new region. Since we have more subscribers than publishers, that makes Active-Passive Publisher a better solution for us.
The result
The result? JustSaying 2.1 supports region failover for messaging using the Active/Passive Publisher model described above. You can grab the NuGet package from the usual place and check out the code on GitHub. The new functionality is straightforward to use; there’s been a non-breaking change to the fluent syntax such that you can, optionally, specify which additional region is used for failover:
...
CreateMeABus
.InRegion("eu-west-1")
.WithFailoverRegion("eu-central-1")
.WithActiveRegion(() => "eu-west-1")
...
This syntax is telling JustSaying to subscribe to messages from both the eu-west-1 and eu-central-1 regions and to publish messages to eu-west-1; the lambda supplied to WithActiveRegion() lets JustSaying know which region to publish messages to. For example, you might want something like this:
WithActiveRegion(() => _activeRegionProvider.CurrentActiveRegion)
In this case ‘_activeRegionProvider’ would be a component responsible for providing the currently active region – perhaps it could read from a config file, a key/value configuration store or an in-memory cache. What works best for you will depend on your environment/scale. That’s all there is to it; no changes are required to your messages or to your message handlers. If you want to change the active region, just update your preferred config file/store/cache.
Live and kicking
Our ambition was to make this functionality straightforward to use so that our teams could upgrade upgrade as painlessly as possible. From that point of view, we’ve been pretty successful: several teams are already using JustSaying 2.1 in production at JUST EAT. Over the next few weeks, we’ll continue this transition so that the platform as a whole becomes resilient to SNS/SQS outages. Interested in seeing how we go about proving a feature in our DevOps environment? Have a look of this previous post and read about performance, graphs and deployments.