We’ve had a lot of success with load testing and the tooling we’ve built to support it. In this post we:
- Give an overview how load testing supports operating at a global scale
- Take a quick peek at the tooling we’ve built to support our test strategy
- Review some of the lessons learned from operating the platform and test tooling over the last three years

At Just Eat we maintain hundreds of software components, with thousands of interactions between them. We serve hundreds of thousands of customers every day, and our platform needs to be as reliable and performant as possible to ensure we can provide the services our food community rely upon. With dozens of teams releasing to this complex environment every day, we needed a way to load and performance test at a scale that mitigates the risks of large scale change in large scale environments.
We maintain a set of performance tests across the organisation. These tests loosely fall into three categories:
Synthetic Monitoring
Our synthetic monitoring continuously executes key business paths which are monitored real-time. They provide a simulated client perspective of the platform.
We’ve also found it useful to have continuous traffic on key paths in test environments. Our synthetic tests tend to align with the most crucial user journeys.
Component Tests
These are the more traditional style of performance tests. They executes against a single component or bounded context. These tests are the earliest to run in the software development life-cycle, providing quick feedback loops.
End to End Tests
These are larger, more comprehensive tests. They are fewer in number and are characterised as executing against multiple components across multiple bounded contexts. They are used to validate change that requires complex system behavior or for combinations of change across domains to ensure key business paths function at scale.
These tests are more expensive to maintain but also tend to find wider-scoped issues that component level performance tests have trouble triggering such as retry-storms.
The Situation
We execute over 300 hours worth of these tests every day across our development, test and production environments. Orchestration of testing at that scale can become cumbersome without supporting tooling to handle the common tasks like launching and configuring load agents, deploying the test scripts and starting and stopping tests.
Our original load test implementations utilised our build and deployment infrastructure to execute tests. However, the networking infrastructure in a typical build server environment isn’t designed to cope with the amount of traffic we generate. Three years ago, we decided to take the opportunity to build a solution that created better control, visibility and ease of use for our engineers, and was able to support the level of complexity in our testing that we needed.
So we built Rambo
We use a bespoke load testing platform we’ve dubbed ‘Rambo’ to manage test configuration, execution and scheduling. Rambo is a container-based scheduler that provides an opinionated implementation to help simplify configuration and uses domain specific language with a custom UI, making it more cognitively friendly to use.
Rambo UI
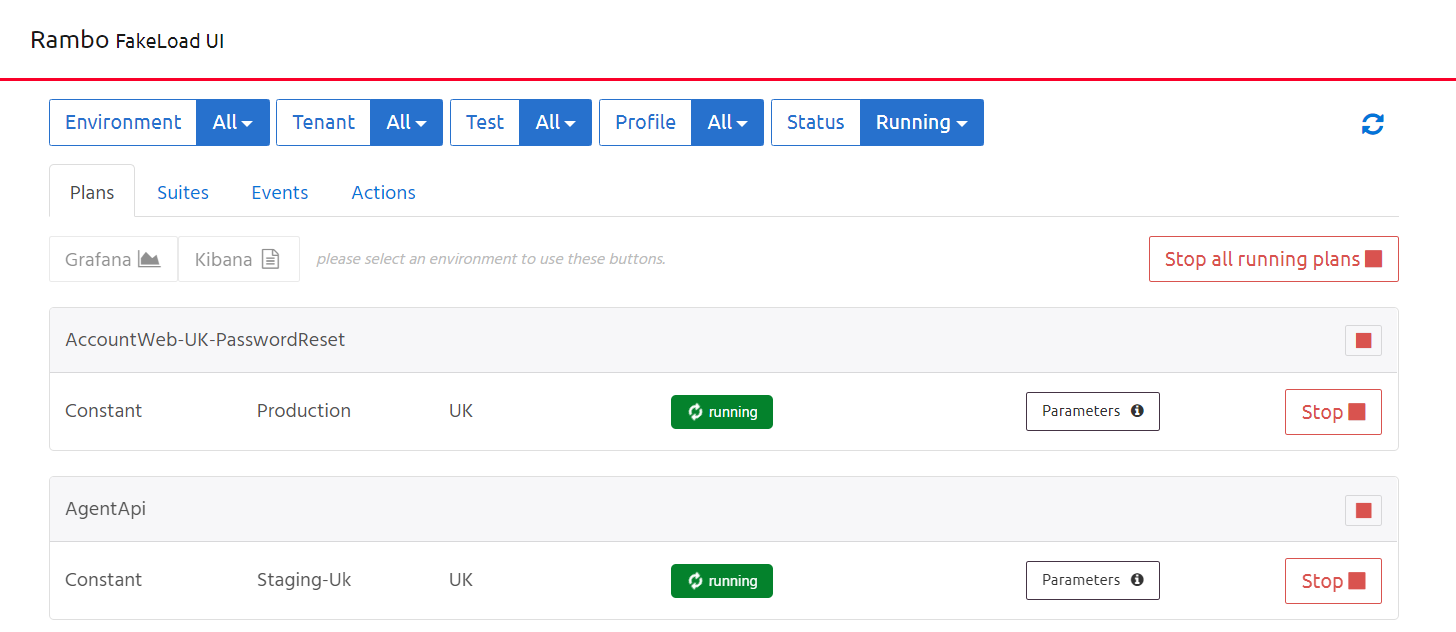
Users can manually manage test execution through the Rambo front-end UI. Tests can be grouped into suites to support larger tests that require multiple load agents or greater test coverage.
Rambo integrates with our monitoring and logging infrastructure to provide live telemetry for executing tests.
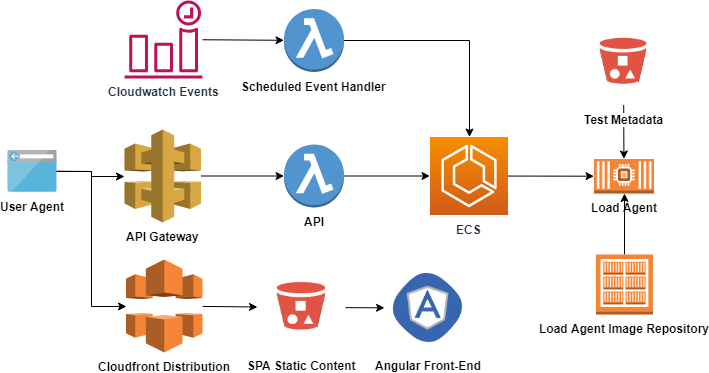
Rambo Architecture
The UI is an Angular single-page application stored in S3 and served via Cloudfront. The API’s primary function is to serve content for the UI and invoke commands against ECS. ECS manages the container orchestration and execution. Scheduled tests and suites are triggered using CloudWatch Events. Tests are defined and configured in source control, and deployed into Amazon S3, which can then be ingested by the API and load agents.
Rambo is deployed into a dedicated VPC with multiple NAT gateways and Elastic IPs. This gives us the greatest control for network configuration ensuring we can effectively maintain the network and diagnose any issues with traffic generation (such as NAT saturation). Large amounts of traffic can be risky to both our production and pre-production environments, so we’ve implemented a number of safety measures to protect our platforms from test traffic.
Protected Production Testing
In order to run against production we often need to bypass our DDOS protection, which forces us to mitigate the risk of DDOSing our own platform. We implement multiple safety mechanisms to help ensure execution of our load tests.
PR validation

Our test metadata is stored in source control. We use validation scripts to check:
- All configuration can be successfully parsed
- Required parameters are populated
- Test scripts don’t contain known configuration that causes memory leaks
- Tests are configured with the correct URLs for their target environments
- Tests pointing at production are using safe load levels
We use a single centralised repository for configuring production tests to mitigate the risk of unknown configurations running against production.
Runtime Protection
Rambo makes assessments at runtime and takes/prevents actions to ensure the safety of the platform. For example:
- Access to Rambo is controlled through ADFS
- Production endpoints cannot be targeted by non-production tests
- Any unrecognised tasks running in ECS are killed immediately
- Any duplicate tasks running in ECS are killed immediately
- Production tests are automatically stopped when approaching peak trading periods
Test Preconditions
Preconditions are pre-test-execution checks which prevent tests from running if failed. For example, if the environment is not scaled sufficiently to handle the load traffic. We calculate what ‘scaled’ means dynamically by interrogating scaling configuration for our components.
Human Factors

In a complex system, automated safety measures cannot always be implicitly relied upon; so any large scale load tests are monitored closely by our engineers in addition to our monitoring and alerting. Our Service Operations Centre (SOC) also have an emergency kill switch in case any test traffic is suspected of causing risk to the production platform.
Important events like tests starting or preconditions failing are logged and posted to a Slack channel for visibility. We also have PagerDuty alerts for our synthetic monitoring on service level indicators such as latency, order rate and error rate.
One of the side-effects of successful large-scale testing is that there’s inevitably contention for shared resources such as test environments. To mitigate this we ensure that we work closely with the SOC and engineers to co-ordinate allocation of resources.
Conclusion
Rambo is a tool we’ve been using for the last three years and it has:
- Helped us ensure our features function successfully at scale
- Allowed us to execute load tests at a moments notice, with a click of a button
- Drive large scale load tests with minimal support required
- Enabled synthetic monitoring and continuous testing
- Enabled a performance-aware software development life-cycle
However, when operating at scale and in production, we’ve had to approach the situation with great care.
We’ve learned:
- Use safe defaults, reduce blast radius and guard your production environments because humans inevitably make mistakes
- Engineers need visibility to make good decisions, and process/constructs to support communication/collaboration
- Test infrastructure should be given the same attention as production infrastructure
- Cover your bases: Supplement human systems with automation and vice versa
- Self-service models allow for process scalability and improved adoption