All we wanted to do was to make things simpler. Remove that bloated code. Deprecate API endpoints. It sounds so simple.
Yet, when you are dealing with components that are built up over time, it can be difficult to see the wood for the trees. Trimming back the technical debt which has been left unmanaged; you just don’t know where to start. Sometimes it can be better just to cut your losses and replace the whole tree!
We broke down our API into its key functional areas and then began moving this functionality to brand new components. This allowed us to avoid breaking production code paths and instead reduce the risk whilst we introduced these over time.
This post will detail the reasons behind this and the process we followed to achieve our end goal.
Background
JustEat’s platform has grown very rapidly from humble beginnings. Humble beginnings in this case means a monolithic architecture. This served Just Eat well for a long period of time but as more load was put on the system, the engineering team grew and the goals of the business grew, the system needed to be split up.
This was done over time, over many different organisational restructures and what we were left with in relation to Search was something like this.
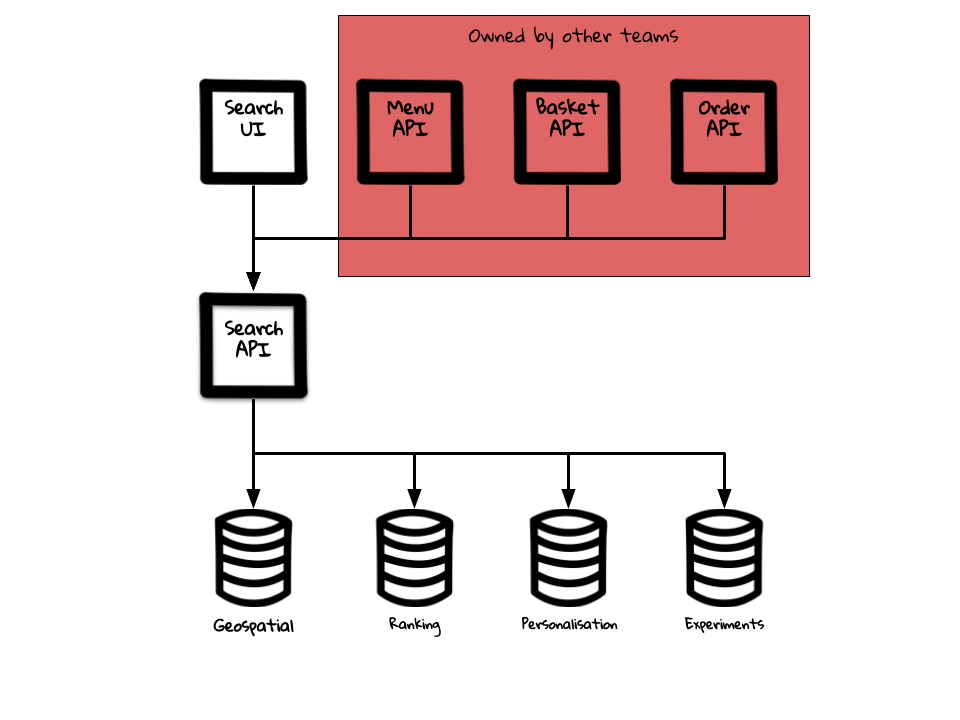
We had an API (aptly named Search API) listening to a single datastore to answer the question “what restaurants are available in an area”. Great!
We then had multiple different components and business domains which used this API to answer this question. For example, to know whether a restaurant is open for delivery, a Basket API would call Search API. To know whether a restaurant had available menus, a Menu API would call Search API. This works, but is starting to sound complex …
We had multiple different teams that wanted to shape the result from this API to allow them to experiment with new ideas and features – adding in additional databases and sources in the process. Hmm, things are getting a little bit too big now!
We had a single point of failure. Oh no. This is not going to end well.
And it didn’t. We had reliability issues which caused outages, all caused from a single component not working properly.

Fast forward
A lot of work was done to improve the reliability of the services we had, doing all the tweaks we needed to get the systems back up and working as expected.
A great deal of work went into improving the reliability of our services, making any changes required to provide a stable platform for our users. We were successful, but we knew we couldn’t stop there. More fundamental changes were needed to ensure we didn’t find ourselves in the same position again in the future.
We started by decoupling our domains across the platform, Search being the first to attempt this journey…
We then had a drive to push for decoupling our domains from each other, Search being one of the first to take on this journey. In doing so, Search API had to be dealt with but we also needed to provide the same backward compatible functionality. So, we began trying to understand what the best approach would be for doing this.
We started by outlining the functionality that this API was actually doing and started dividing it up so it could be better managed, developed upon and kept reliable.
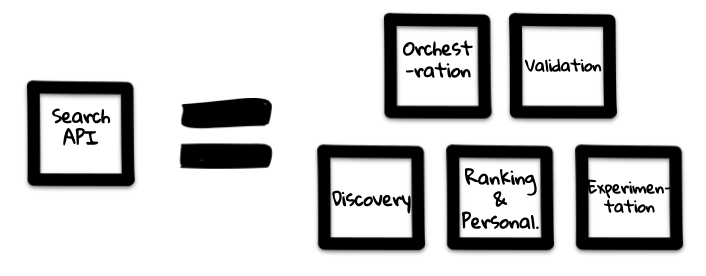
We identified that this one API actually had 5 key pieces of functionality, all being used in different ways
- Orchestration – Taking all of the data sources, combine into a single contract which can be consumed by client services (apps, websites etc).
- Validation – Based on the address entered, make sure that restaurants can deliver to them.
- Restaurant Discovery – Answering the basic question from above,”what restaurants are available in an area”.
- Personalisation and Ranking – Based on key information (consumer preferences, distance, restaurant performance and others) filter or modify the restaurants returned for the given request.
- Experimentation – Based on a given request, change/modify behaviour or data so that we can test changes to designs easily.
This is a lot for a single API to be doing. So we began splitting things up along the boundaries that have been defined above and the teams that own them.
Taking each piece of functionality, we added in new components in and around our existing infrastructure (so not to break things) and slowly began to rewire our domain. Over the course of 12 months we went from:
to;
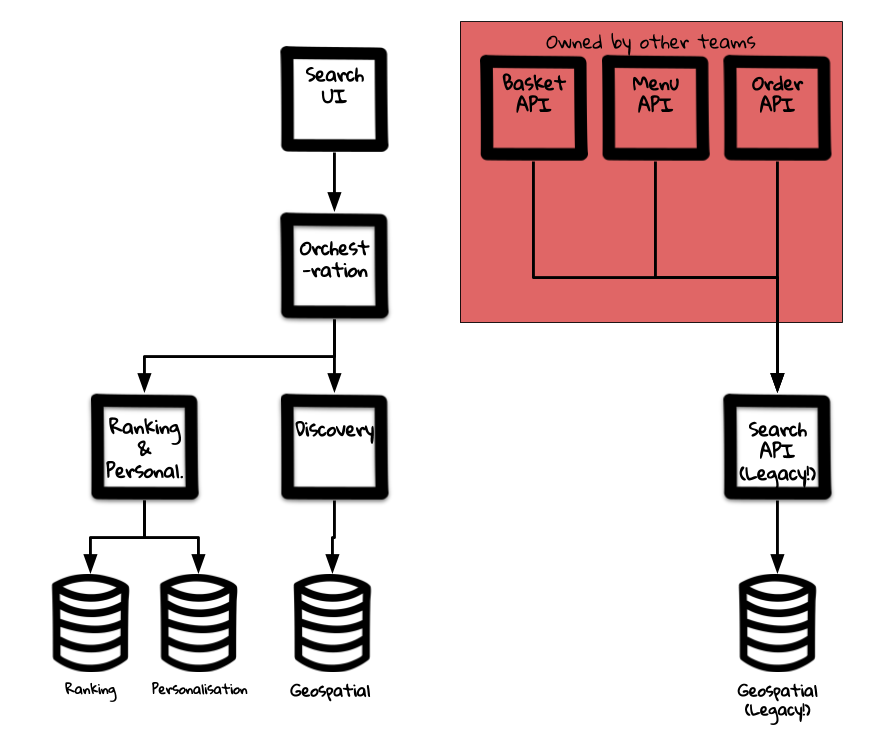
By doing this we have been able to reduce the bottleneck caused by our single point of failure. This also allowed for us to continue supporting other business requirements whilst reducing the impact this has on our domain. For example, we are now able to release changings with more confidence and speed, given that the potential impact has been limited to only the components that we own.
The older Search API has been put into a maintenance mode – where no new features are being implemented and only bug fixes are being made – and other parts of the business can prioritise removing the dependencies.
This had fitted in nicely to allow us to progress with modifying and tidying up our codebase without being restricted by the demands of stakeholders elsewhere in the business who might have other priorities.
We could have put effort into decoupling the existing APIs from other places in the business, however this would have taken time and effort and require our teams to build up knowledge of other domains first. Instead, the approach we have taken means we unblock ourselves and are less reliant on large scale organisational alignment.
Obviously this doesn’t come without risk and complexity that goes along with many more, smaller components.
I will leave how we actually progressed from before to after to another post where we will focus more on how one of these smaller services was rolled out to production successfully.